Recommendations text processing
The Full data processor block gets engaged when the Site Administrator has chosen the Full Hybrid mode from Quick-access menu > Plugins > Machine learning settings > Recommender engine, which will be accessible when the machine learning plugins are enabled. This block processes the natural language and transforms the processed text into a TF-IDF matrix which will eventually be used by the machine learning model. This block uses some external resources to process the text. These resources are distributed under a variety of licences for each language that Totara supports. The extent of text processing this block does depends on the type of external resources available on the machine the engine is running on.
Language resources
The Recommender engine can utilise one of the three types of language resources to clean and transform the free text for each language. The library langdetect is used for detecting the language of the text and is installed through the requirements.txt file and distributed under the Apache MIT licence. The engine chooses the best available resource for a language to clean and lemmatise the text in the order of spaCy language models, spaCy lookups data, and Stopwords ISO; the spaCy language models being the best resource.
Installation of language resources
The spaCy lookups data and the Stopwords ISO are listed in the requirements.txt file and will be installed when the Recommenders engine is set up.
The spaCy language models are available under variety of licences and not all of them can be distributed with the Recommenders engine. It is left for the Site Administrator to install the model of the language in which their main content is written (and which the model licence allows). You can install the language models using the following command:
python -m spacy download [lang]_[type]_[genre]_[size]
In this code, [lang]_[type]_[genre]_[size] is the model name under spaCy's naming convention. Here:
- Lang: Language code
- Type: Capabilities (e.g.
corefor general-purpose pipeline with vocabulary, syntax, entities and word vectors, ordepfor vocab and syntax only) - Genre: The type of text on which the pipeline is trained, e.g.
webornews - Size: Package size indicator (
sm,mdorlg)
The language models for installation and their licences can be found at spaCy language models. The lookups data tables and the stopwords are installed through the requirements.txt file and have the MIT licence.
For TF-IDF, transformation of the processed text happens using the scikit-learn library that is distributed under the BSD 3-Clause licence.
Text processing model
The text cleaning and transformation process can be explained using a flowchart as below:
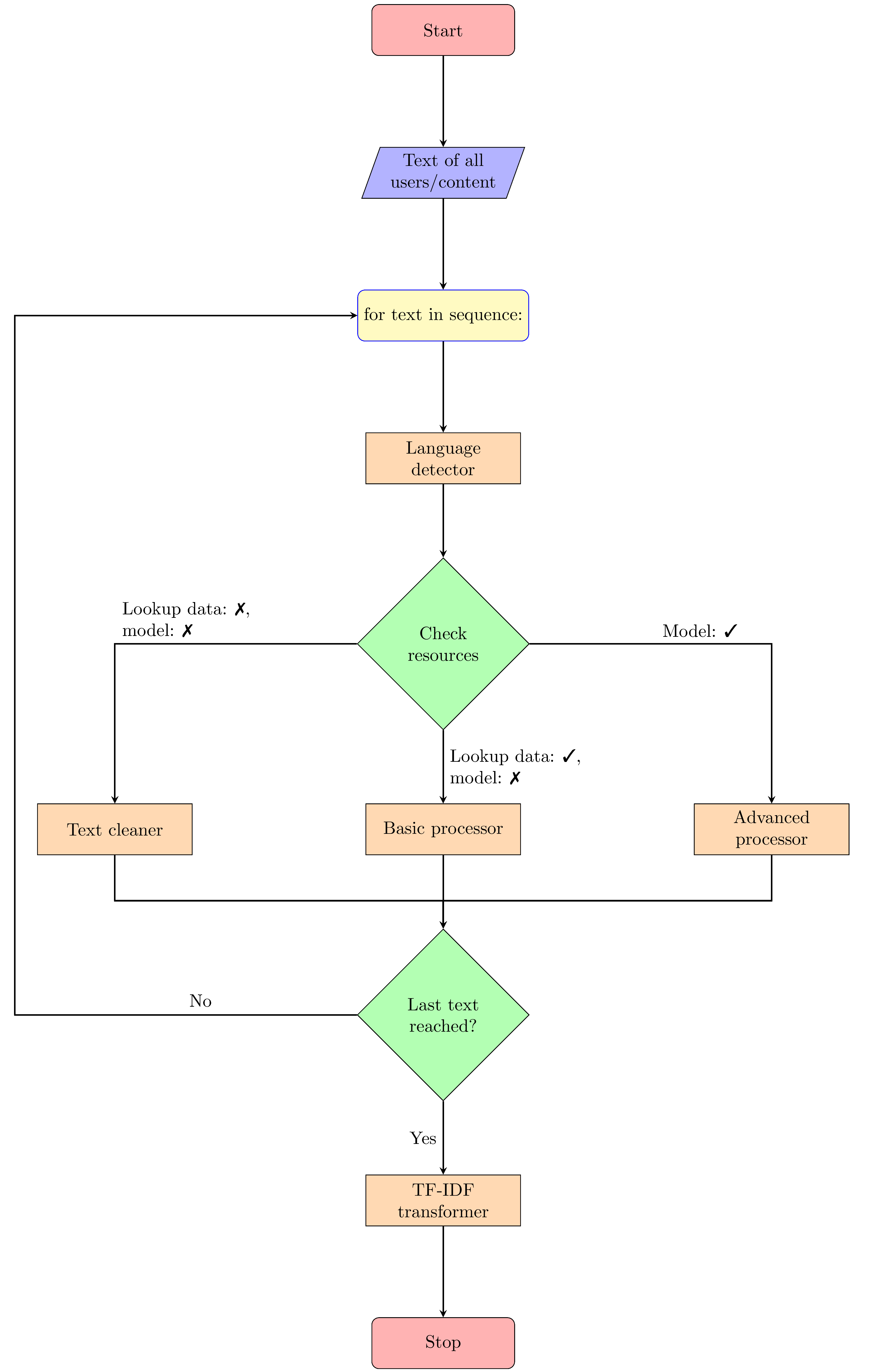
The input of the natural language processing block is either a list of free text of all content, or all users. The block iterates over the entire list for documents and does the following:
- Predicts the language of the document.
- Looks for the available processing resources for the predicted language and chooses the best one.
- Depending upon the type of resource available, it cleans/lemmatises the document.
The language processing blocks are summarised below.
Language detector
A predictive language detector is used to predict the language in which the text is written. This helps in further cleaning/transformation processes.
Text cleaner/lemmatiser
Depending on which language resources are available, the text is directed to one of the Text cleaner, Basic processor, or Advanced processor blocks.
Each block is summarised below.
Text cleaner
If the document that is being processed is in a language that does not have model and lookups data available, the processor directs the document to the Text cleaner. The Recommendation engine code is distributed with a set of stop-words of 58 languages. The Text cleaner replaces the words with their lowercase versions, removes URLs, email addresses, punctuation, etc., then removes all the stop-words from the document (if stop-words for the language are available), and finally returns the 'cleaned' text document.
Basic processor
The spaCy distributes lookup data tables which are used with the main spaCy framework to remove stop-words, and other text cleaning functions for each language. All of these lookup data tables are distributed under the MIT licence. The lookup data tables provide mapping from raw words to their origin words (or lemmas). The lemmatisation is a great tool which helps to reduce the size of the entire bucket of unique words. This means that words that have similar context or meaning are grouped together. For example, the words 'trouble', 'troubling', 'troubled', and 'troubles' are all reduced to the same word 'trouble'. If these words were not replaced with their lemma, the subsequent machine learning algorithm would consider them entirely different features or variables with no connection to each other.
Advanced processor
The spaCy has full model support for some languages. These models support in identifying if each word is URL-like, email address-like, like a number, punctuation, a stop-word, etc. This functionality helps to clean the text with greater accuracy. The lookup data tables merely provide a mapping from words to lemmas, whereas in reality words change their meaning (or therefore lemmas) depending upon the context of their use. This can be effectively achieved using the models which are pre-trained on large 'tagged' or 'mapped' text data sets.
These models are distributed by spaCy under variety of licences. Some restrict re-distribution for commercial purposes.
TF-IDF transformer
Once the text cleaning/lemmatisation is done, the TF-IDF transformer block transforms the entire set of processed documents into a TF-IDF matrix. This numerical matrix is subsequently used in Machine Learning Algorithm.