Implementing GraphQL services
This section describes how to create new GraphQL services within Totara as a developer. As a prerequisite, you should familiarise yourself with the core concepts of GraphQL by working through the GraphQL tutorial first. You may also be interested in Using our APIs.
When implementing GraphQL services, there are a number of number of concepts and files which are needed. This document describes each of them and explains how they fit together. There are five main file locations, three of which use the GraphQL language, and two of which are in PHP:
- Query definitions (GraphQL schema)
- Type definitions (GraphQL schema)
- Persisted queries (GraphQL)
- Query and mutation resolvers (PHP)
- Type resolvers (PHP)
In addition, resolvers can make use of middleware to abstract common code and apply it to multiple resolvers.
Query definitions
Query definitions describe the query entry points into the GraphQL schema. You could think of each query as being like a specific service that an API user can call on. For a request to be successful, the top level of any GraphQL query has to match a valid query definition in the schema. Query definitions have a name, possibly some required and/or optional arguments, and they return a Type. These top-level queries specify what items are returned, but don't specify the content of each item other than the type of the data. The content itself is determined further down the chain by the Type resolvers.
File locations
lib/webapi/*.graphqls - query definitions for all core code (including core components) that will apply to all endpoint types.
lib/webapi/$endpoint_type/*.graphqls - query definitions for core code (including core components) that will apply to a specific endpoint type.
plugindir/webapi/*.graphqls - query definitions for plugins to extend core schema that will apply to all endpoint types.
plugindir/webapi/$endpoint_type/*.graphqls - query definitions for plugins to extend core schema that will apply to a specific endpoint type.
Note there can be multiple files which are merged together to help with schema organisation, but if there is only one file, our convention is to call it schema.graphqls.
Example structure
In the primary schema file lib/webapi/schema.graphqls the structure is:
type Query {
core_template(name: param_alphanumext!, component: param_component!, theme: param_theme!) : String!
}
In any other *.graphql files, when extending core, the structure is:
extend type Query {
totara_job_my_assignments: [totara_job_assignment!]!
}
Note that GraphQL does not support namespaces, so in order to avoid collisions and identify the correct resolver, the query definition name is expected to be in the format {$component}_{$queryresolverclassname}.
Type definitions
Type definitions are also stored in the schema files. While their structure is essentially identical to query definitions (technically the top level Query is a type), they are handled differently when a query is actually run, so the distinction is important. Types contain fields which each have their own type. Types eventually have to resolve down to scalar values (meaning a single non-complex value is returned).
File locations
lib/webapi/*.graphqls - type definitions for all core code that will apply to all endpoint types.
lib/webapi/$endpoint_type/*.graphqls - type definitions for all core code that will apply to a specific endpoint type.
plugindir/webapi/*.graphqls - type definitions for plugins to extend core schema that will apply to all endpoint types.
plugindir/webapi/$endpoint_type/*.graphqls - type definitions for plugins to extend core schema that will apply to a specific endpoint type.
Example structure
In the primary schema file lib/webapi/schema.graphqls the structure is:
type core_lang_string {
lang: String!,
identifier: String!
component: String!
string: String!
}
In plugin *.graphqls files they look the same:
type totara_hierarchy_position_type {
id: core_id!
fullname(format: core_format = HTML) : String!
idnumber : String
shortname(format: core_format = HTML) : String
description(format: core_format = HTML) : String
}
Type definition names are expected to be in the format {$component}_{$typeresolverclassname}.
Persisted queries
Persisted queries are the last concept that uses the GraphQL language. While the concepts above define the GraphQL schema that the server makes available, persisted queries provide a way to request data from the server. Persisted queries make use of a query definition, but specify exactly which fields you want to get back. They can optionally have variables for populating parameters to be passed to the query. At Totara we've made the call to require persisted queries for the AJAX and mobile endpoints, which means the front end can't make arbitrary queries, you have to create a persisted query in a file and reference that. This makes the front-end code simpler and also more secure, as users can't execute arbitrary queries. On the other hand, the developer and external endpoints use arbitrary queries, so when using them you need to specify the full query definition.
Persisted queries start from a top-level query definition, then specify which fields they want. They can be nested to return deep hierarchies of data by taking advantage of the relationships defined in the schema.
Persisted queries can be defined by any component. One component might have a number of quite similar persisted queries for different purposes, and different components can also have similar queries. There's no problem with that at all. This means each query can fetch only the data it needs. You shouldn't define arbitrary persisted queries in your component for the sake of it. Only define them when you need it in order to make an AJAX request for that data. If third parties want to make use of the AJAX or mobile GraphQL API, they can create their own local plugins which define the queries they need.
Since you can request any data you want in a persisted query, including heavily nested complex queries, as a developer you need to consider the performance impact when writing the query. Don't do anything too crazy in terms of complex nesting. If you need something that you know will be very expensive, you might be better off creating a new dedicated query definition, which can be optimised to efficiently gather the data you need.
File locations
lib/webapi/ajax/persistedquery.graphql - persisted query in core.
user/webapi/ajax/persistedquery.graphql - persisted query in core subsystem.
plugindir/webapi/ajax/persistedquery.graphql - persisted query in plugin.
Example structure
query totara_job_assignments($userid: core_id!) {
totara_job_assignments(userid: $userid) {
id
shortname
fullname
idnumber
managerja {
user {
fullname
}
}
appraiser {
fullname
}
}
}
In the example above, the first reference to totara_job_assignments is the name of the persisted query. The second reference to totara_job_assignments matches the 'query definition' in the schema.graphqls file. The other fields represent the fields to be returned. $userid is a variable that must be passed when the query is used.
GraphQL supports fragments, which can allow for reuse of sections of a query. Note that Totara does support fragments within a persisted query file, but you cannot currently define fragments for reuse across the entire schema.
Extending persisted queries
To update the fields returned by a persisted query, it is recommended that the existing query is copied into a new extended_query.graphql file, and the changes are made there. This will decrease the potential for conflicts during future upgrades, and make the change more maintainable. As long as any fields added are already defined in the schema, then they would only have to be added to the new query. Calls to the original query can be switched the extended one on a case-by-case basis.
For example, if you wanted to add position/organisation fields to the totara_job_assignments query above, it could be extended by copying the file to an extended_totara_job_assignments.graphql, which would then look something like this:
Example structure
query extended_totara_job_assignments($userid: core_id!) {
totara_job_assignments(userid: $userid) {
id
shortname
fullname
idnumber
managerja {
user {
fullname
}
}
appraiser {
fullname
}
position {
fullname
}
organisation {
fullname
}
}
}
Query resolvers
Query resolvers are defined in PHP on the back end. The query resolver's job is to get the data required to allow the requested query to be returned. That includes responsibility for checking access control (require_login) and permissions to ensure the user is allowed to access the data, and for querying the model/database to fetch the raw data.
When a particular query contains nested components (e.g. items of another type nested within the original type), the query resolver will typically request the raw data for child items, but only for one level of nesting. The next level would be obtained from the type resolver.
Note that there are a couple of things that the query resolver doesn't do:
- Formatting the raw data in the correct format to be returned (that is done by this item's type resolver)
- Handling calculation of fields' nested components (that is done by the child item's type resolver)
File locations
lib/classes/webapi/resolver/query/myqueryresolver.php - query resolver in core.
user/classes/webapi/resolver/query/myqueryresolver.php - query resolver in core subsystem.
plugindir/classes/webapi/resolver/query/myqueryresolver.php - query resolver in plugin.
Example structure
namespace totara_job\webapi\resolver\query;
class assignment extends \core\webapi\query_resolver {
public static function resolve(array $args, execution_context $ec) {
// Complete permission checks, then return the appropriate
// raw data required by this query, which is then passed
// to the type resolver for final processing.
}
}
How you implement your resolvers is up to you, however a common pattern that we use involves applying a formatter to an ORM model object. This provides a consistent approach to implementing resolvers which meets the single responsibility principle and allows for testing and code reuse. See the Formatters page more details.
We also offer an option to implement middleware to further reduce duplication by abstracting out common patterns that apply to multiple resolvers.
Type resolver
Type resolvers are defined in PHP on the backend. The type resolver's job is to take the raw data from the query resolver and return the actual data requested. Type resolvers are called over and over by the query resolver for each field that's requested - each time the resolver will be passed the name of the field being requested, as well as the raw data object. The type resolver deals with things like output formats when the same data can be requested in different formats via the query.
When calculating the value of a scalar field, the type resolver does not deal with access control - that must be implemented in the query resolver. When the field being requested is itself a complex type, the type resolver may need to load the raw data (similar to what the query resolver does) and return that, if it has not been preloaded by the query. In that situation, the type resolver must enforce access control over the specific data that is generated. The raw data will then be passed to the child type's type resolver for further processing.
To give an example, imagine a category type which contains a 'courses' field that returns an array of courses within the category. When the type resolver returns properties belonging the category, such as name or idnumber, the type resolver can assume that the user is allowed to see the category (because the query is responsible for only requesting categories that the user can see). However, when generating the raw data for the courses field that will be passed to the course type resolver, it is important that only courses the user is allowed to see are returned.
File locations
lib/classes/webapi/resolver/type/mytyperesolver.php - type resolver in core.
user/classes/webapi/resolver/type/mytyperesolver.php - type resolver in core subsystem.
plugindir/classes/webapi/resolver/type/mytyperesolver.php - type resolver in plugin.
Example structure
namespace totara_job\webapi\resolver\type;
class assignment implements \core\webapi\type_resolver {
public static function resolve(string $field, $job, array $args, execution_context $ec) {
// For a given $field name, use the $job object, query $args and any execution context
// to return the correct specific value for that field (for scalars) or the relevant
// raw data required by the type resolver (for complex types).
}
}
Allocation of work between type and query resolvers
Since it is the job of both the query resolver and the type resolver to produce the final output, there is some flexibility as to exactly how to distribute the work between the two classes. There is no formal declaration of the structure of the return value from the query resolver. In general, the query resolver should return the basic object and all data associated with it that doesn't require a lot of extra work to calculate. The extra work to get child properties that may or may not be needed would be done in the type if that property has been requested only. Note, however, that anything requested in a type resolver may be called many times during a request (which can have a performance impact), whereas query and mutation resolvers are typically called just once. There are some ways that this performance impact can be mitigated, see GraphQL performance for details.
Overall process
The diagram below shows the code control flow, with colours indicating the passing of specific data between layers.
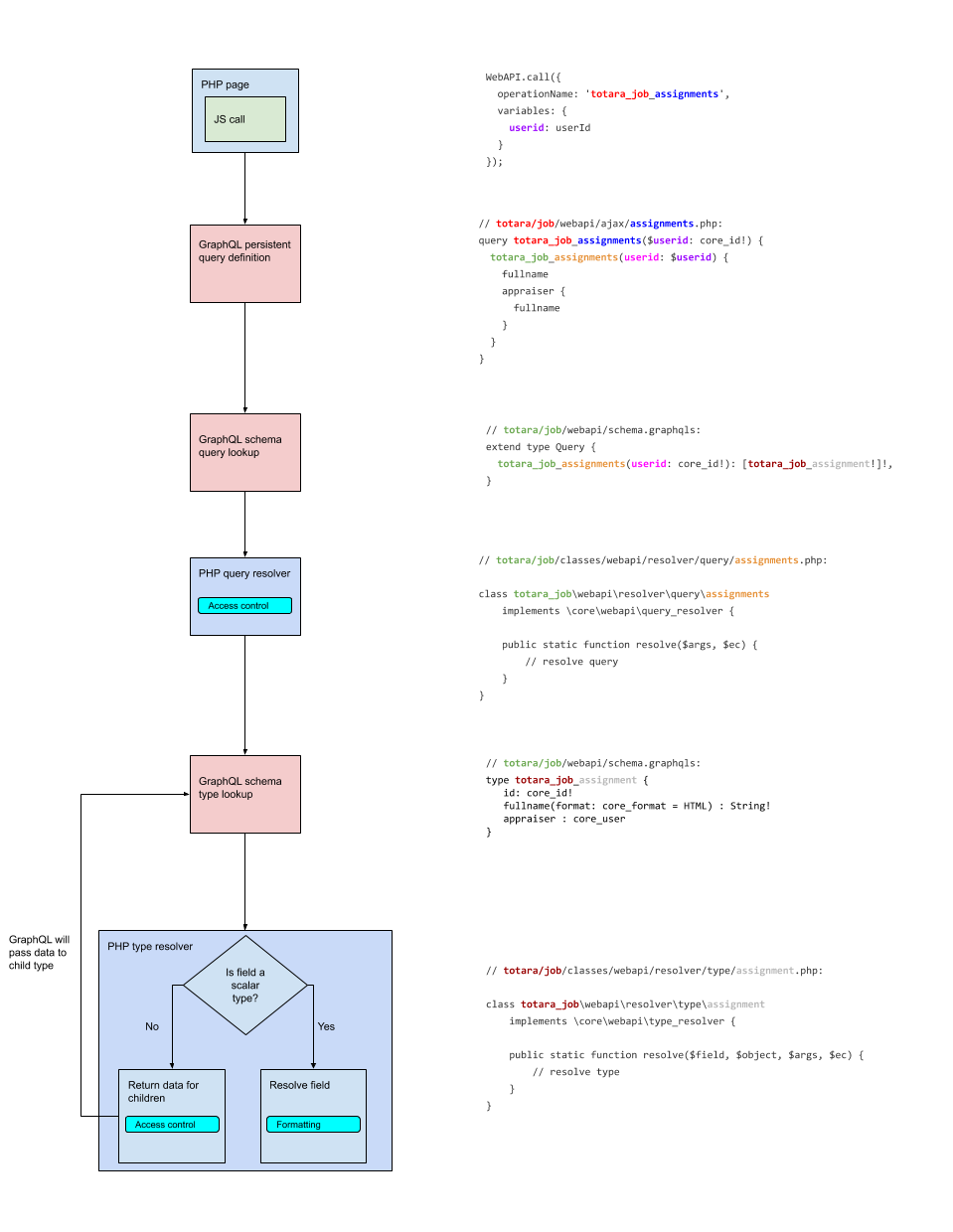
When making an AJAX GraphQL request from JavaScript, your request might look like this (if you were using the raw JS request function):
WebAPI.call({
operationName: 'totara_job_assignments',
variables: {
userid: userId
}
})
Here totara_job_assignments is the name of the persisted query you want to execute. The structure of the operationName is {$component}_{$queryname}, so in this case it will look up the assignments query in the totara_job component. So, it will execute the query located in totara/job/webapi/ajax/assignments.graphql, passing in the variables defined in JS.
In this case, the query looks like this:
query totara_job_assignments($userid: core_id!) {
totara_job_assignments(userid: $userid) {
id
shortname
fullname
idnumber
managerja {
user {
fullname
}
}
appraiser {
fullname
}
}
}
Note that totara_job_assignments on the first line is the name of this particular persisted query. totara_job_assignments on the second line refers to a query definition in the schema.
To figure out what to do with this query, GraphQL will look at the schema. In this case, the schema has been extended by the totara/job component to add a new query definition via its own schema file located in totara/job/webapi/schema.graphqls:
extend type Query {
...
"""
Query to return all of the given users job assignments
"""
totara_job_assignments(userid: core_id!): [totara_job_assignment!]!,
...
}
This schema query definition describes arguments and return types for the query. So in this case, userid is required, and the query will return an array of items of type totara_job_assignment. The totara_job_assignment type is also defined in the schema:
type totara_job_assignment {
id: core_id!
userid: core_id!
user: core_user!
fullname(format: core_format = HTML) : String
shortname(format: core_format = HTML) : String
idnumber : String!
description(format: core_format = HTML) : String
startdate: core_date
enddate: core_date
positionid: core_id
position: totara_hierarchy_position
organisationid: core_id
organisation: totara_hierarchy_organisation
managerjaid: core_id
managerja: totara_job_assignment
tempmanagerjaid: core_id
tempmanagerja: totara_job_assignment
tempmanagerexpirydate(format: core_date_format = TIMESTAMP) : core_date
appraiserid: core_id
appraiser: core_user
staffcount: Int!
tempstaffcount: Int!
}
Here you can see that some of the fields in the totara_job_assignment type are scalar fields that will return an actual value (such as fullname), whereas other fields are complex types (such as core_user or totara_hierarchy_position).
If the query provides the required arguments, the execution of the query is passed to the query resolver. Because the query is totara_job_assignments, GraphQL will look for the assignments query resolver in the totara_job component. That is located in totara/job/classes/webapi/resolvers/query/assignments.php.
The query resolver's resolve() method receives the query arguments (as the $args argument). This is used to check permissions and then query the core platform to obtain the raw job assignment data. Assuming the query resolver returns without exceptions, GraphQL will now call the type resolver in order to convert the raw job assignment data to the final form. Because the totara_job_assignments query signature returns an array of totara_job_assignment type items, GraphQL knows to pass the job data to the assignment type resolver from the totara_job component, found in totara/job/classes/webapi/resolver/type/assignment.php.
The resolve() method in the type resolver is called for every field being requested, and is passed the following:
- The name of the field being requested
- The raw job data from the query resolver
- The query arguments
- The execution context which contains any other contextual data that might be relevant/useful
In the query above you can see that the appraiser field is a complex type (returning core_user instead of a scalar value). Therefore when the type resolver requests that field, it behaves slightly differently:
case 'appraiser':
if (empty($job->appraiserid)) {
return null;
}
// This will throw an exception if the user cannot be found.
return new core\entity\user($userid);
Instead of returning a scalar value it is returning a user record.
Because the appraiser field in the totara_job_assignment type is of type core_user, the user record is then passed to the core_user type resolver for further processing. The process will continue working its way down, resolving every type requested until everything has been resolved to a scalar type.
Returning error responses
When developing resolvers, sometimes it is necessary to throw errors to the user. This could be due to a user input error (validation issues with input data), a permissions issue, or some problem on the system side.
The GraphQL library sets an error handler to automatically catch exceptions and reformat them for output so the correct way of handling errors is to throw an exception. Since each resolver has any thrown exceptions caught separately, it's possible for a request to return multiple separate exceptions if different parts of the request fail (or one part fails multiple times).
The most basic way is to define a dedicated exception class and throw an exception of the appropriate type, with a message indicating the problem:
if (empty($name)) {
throw new create_client_exception('The client name cannot be blank.');
}
In production mode this will result in a generic error message without any specific detail:
"errors": [
{
"message": "Internal server error",
"extensions": {
"category": "internal"
},
"locations": [ ... ],
"path": [ ... ]
}
]
When debugging is enabled, the stack trace will be included along with the debugMessage property that will contain the exception string, but the message is still 'Internal server error':
[
{
"debugMessage": "The client name cannot be blank.",
"message": "Internal server error",
"extensions": {
"category": "internal"
},
"locations": [ ... ],
"path": [ ... ],
"trace": [ ... ]
}
]
If you want to expose more information to the end user, the exception should be generated as a client_aware_exception as follows:
if (empty($name)) {
$e = new create_client_exception('The client name cannot be blank.');
throw new client_aware_exception($e, ['category' => 'example category']);
}
Which would result in the following in production mode:
[
{
"message": "The client name cannot be blank.",
"extensions": {
"category": "example category"
},
"locations": [ ... ],
"path": [ ... ],
}
]
And in development mode:
[
{
"message": "The client name cannot be blank.",
"extensions": {
"category": "example category"
},
"locations": [ ... ],
"path": [ ... ],
"trace": [ ... ]
}
]
Categories can be used to group errors by a specific type, which can help the client making the request to respond differently to different types of errors.
Note that we don't typically internationalise (translate) coding error strings in the external API - they are all hardcoded in British English as that is the language used for Totara development.
Error handling
Currently, there is no special guidance on how to handle errors. The typical approach is to throw an exception in the PHP code, and any uncaught exceptions are returned by GraphQL in a structured way described in Using GraphQL APIs. The front end is then free to handle those errors (if it knows how), or if they are unhandled, a generic error handler will expose them to the end user via a dialog.
GraphQL concepts to support reusability
In order to format your data for output via GraphQL, we offer a reusable mechanism called Formatters. See GraphQL formatters for more details.
We also support middleware and middleware groups to provide a mechanism to reuse common patterns across resolvers. See GraphQL Middleware for more information.
Performance
See GraphQL performance for more details on how resolver implementation can impact performance and how you can develop performant APIs.
Debugging
When developing, you are likely to want to run a local site in development mode so you can see full errors in your API responses. See Enabling debugging in GraphQL APIs for details.
Licensing
The PHP code on the back end that implements GraphQL services depends on Totara's core framework, which is licensed as GPL version 3 or later. Due to the viral nature of the GPL, service implementations will typically need to be licensed the same way.
Any external code that makes use of the API is free to choose any licence they see fit.